环境说明
OS: Centos7.5
Kubernetes: 1.15.4
Docker: 18.09
| 主机名 | IP / VIP | 组件 |
|---|---|---|
| k8s-master1 | 192.168.10.81 / 192.168.10.80 | haproxy、keepalived、etcd、kube-apiserver、kube-controllet-manager、kube-scheduler、node |
| k8s-master2 | 192.168.10.82 / 192.168.10.80 | haproxy、keepalived、etcd、kube-apiserver、kube-controllet-manager、kube-scheduler、node |
| k8s-master3 | 192.168.10.83 / 192.168.10.80 | haproxy、keepalived、etcd、kube-apiserver、kube-controllet-manager、kube-scheduler、node |
| k8s-node1 | 192.168.10.84 | kubelet、kube-proxy、docker、calico、core-dns |
| k8s-node2 | 192.168.10.85 | kubelet、kube-proxy、docker、calico、core-dns |
环境准备
配置host1
2
3
4
5
6
7cat >> /etc/hosts <<EOF
192.168.10.81 k8s-master1
192.168.10.82 k8s-master2
192.168.10.83 k8s-master3
192.168.10.84 k8s-node1
192.168.10.85 k8s-node2
EOF
免密钥1
2
3
4
5
6
7
8
9
10
11
12yum install -y expect
ssh-keygen -t rsa -P "" -f /root/.ssh/id_rsa
export mypass=123456
name=(k8s-master1 k8s-master2 k8s-master3 k8s-node1 k8s-node2)
for i in ${name[@]};do expect -c "
spawn ssh-copy-id -i /root/.ssh/id_rsa.pub root@$i
expect {
\"*yes/no*\" {send \"yes\r\"; exp_continue}
\"*password*\" {send \"$mypass\r\"; exp_continue}
\"*Password*\" {send \"$mypass\r\";}
}";done
hostname1
2
3
4
5name=(k8s-master1 k8s-master2 k8s-master3 k8s-node1 k8s-node2)
for i in ${name[@]};do scp /etc/hosts root@$i:/etc/;done
name=(k8s-master1 k8s-master2 k8s-master3 k8s-node1 k8s-node2)
for i in ${name[@]};do ssh root@$i hostnamectl set-hostname $i;done
关闭防火墙、selinux、swap1
2
3
4
5
6
7
8systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
iptables -F && iptables -X && iptables -F -t nat && iptables -X -t nat
iptables -P FORWARD ACCEPT
swapoff -a
sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
升级内核1
2
3
4
5
6
7#Docker overlay2需要使用kernel 4.x版本
rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm
yum --enablerepo=elrepo-kernel install -y kernel-lt
grub2-set-default 0
grub2-mkconfig -o /etc/grub2.cfg
grubby --default-kernel
reboot
kernel1
2
3
4
5
6cat >/etc/sysctl.d/k8s.conf <<EOF
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
EOF
sysctl --system
ipvs1
2
3
4
5
6
7
8
9
10
11yum install -y conntrack ipvsadm ipset
cat >/etc/modules-load.d/ipvs.conf << EOF
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack
EOF
modprobe ip_vs_rr nf_conntrack
lsmod | egrep "ip_vs_rr|nf_conntrack"
时间同步1
2
3yum install -y ntpdate
echo "*/30 * * * * ntpdate time7.aliyun.com >/dev/null 2>&1" >> /var/spool/cron/root
ntpdate time7.aliyun.com
cfssl
1 | curl -L -o /usr/local/bin/cfssl https://pkg.cfssl.org/R1.2/cfssl_linux-amd64 |
https://coreos.com/os/docs/latest/generate-self-signed-certificates.html1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47mkdir ~/cfssl && cd ~/cfssl
#cfssl print-defaults config > ca-config.json
cat > ca-config.json <<EOF
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"kubernetes": {
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
],
"expiry": "87600h"
}
}
}
}
EOF
#cfssl print-defaults csr > ca-csr.json
cat > ca-csr.json <<EOF
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "GuangZhou",
"L": "GuangZhou",
"O": "k8s",
"OU": "System"
}
],
"ca": {
"expiry": "87600h"
}
}
EOF
cfssl gencert -initca ca-csr.json | cfssljson -bare ca
1 | cat > etcd-csr.json <<EOF |
etcd
https://github.com/coreos/etcd/releases1
2
3
4
5
6
7
8
9
10
11mkdir -p etcd
mkdir -p etcd/ssl
cp ~{ca.pem,etcd.pem,etcd-key.pem} etcd
cd local/src
wget https://github.com/etcd-io/etcd/releases/download/v3.4.1/etcd-v3.4.1-linux-amd64.tar.gz
tar xf etcd-v3.4.1-linux-amd64.tar.gz
cp etcd-v3.4.1-linux-amd64/{etcd,etcdctl} local
ETCDHOSTS=(192.168.10.81 192.168.10.82 192.168.10.83)
for i in ${ETCDHOSTS[@]}; do scp localetcd* root@$i:local; done
etcd.service1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40ETCDHOSTS=(192.168.10.81 192.168.10.82 192.168.10.83)
NAMES=("etcd-0" "etcd-1" "etcd-2")
for i in "${!ETCDHOSTS[@]}"; do
HOST=${ETCDHOSTS[$i]}
NAME=${NAMES[$i]}
cat << EOF > /tmp/etcd.service.${HOST}
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
Type=notify
ExecStart=/usr/local/bin/etcd \\
--data-dir=/data/etcd \\
--name=${NAME} \\
--trusted-ca-file=/etc/etcd/ssl/ca.pem \\
--cert-file=/etc/etcd/ssl/etcd.pem \\
--key-file=/etc/etcd/ssl/etcd-key.pem \\
--peer-trusted-ca-file=/etc/etcd/ssl/ca.pem \\
--peer-cert-file=/etc/etcd/ssl/etcd.pem \\
--peer-key-file=/etc/etcd/ssl/etcd-key.pem \\
--peer-client-cert-auth \\
--client-cert-auth \\
--listen-peer-urls=https://${HOST}:2380 \\
--initial-advertise-peer-urls=https://${HOST}:2380 \\
--listen-client-urls=https://${HOST}:2379,http://127.0.0.1:2379 \\
--advertise-client-urls=https://${HOST}:2379 \\
--initial-cluster-token=etcd-cluster-0 \\
--initial-cluster=${NAMES[0]}=https://${ETCDHOSTS[0]}:2380,${NAMES[1]}=https://${ETCDHOSTS[1]}:2380,${NAMES[2]}=https://${ETCDHOSTS[2]}:2380 \\
--initial-cluster-state=new
Restart=on-failure
RestartSec=5
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
done
1 | ETCDHOSTS=(192.168.10.81 192.168.10.82 192.168.10.83) |
集群时间不对报错,注意同步下时间1
2
3
4Oct 10 03:36:05 node1 etcd: rejected connection from "192.168.10.83:52514" (error "remote error: tls: bad certificate", ServerName "")
Oct 10 03:36:05 node1 etcd: rejected connection from "192.168.10.83:52518" (error "remote error: tls: bad certificate", ServerName "")
Oct 10 03:36:05 node1 etcd: rejected connection from "192.168.10.82:57950" (error "remote error: tls: bad certificate", ServerName "")
Oct 10 03:36:05 node1 etcd: rejected connection from "192.168.10.82:57952" (error "remote error: tls: bad certificate", ServerName "")
haproxy
1 | yum install -y haproxy |
1 | cat > /etc/haproxy/haproxy.cfg <<EOF |
keepalived
1 | yum install -y keepalived psmisc |
1 | cat > /etc/keepalived/keepalived.conf <<EOF |
docker
https://v1-15.docs.kubernetes.io//docs/setup/release/notes/ ctrl+f docker version1
2
3
4yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
#yum list docker-ce --showduplicates | sort -r
yum install -y docker-ce-18.09.8
1 | mkdir /etc/docker |
kubeadm install
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
https://v1-15.docs.kubernetes.io/docs/setup/production-environment/tools/kubeadm/high-availability/
1 | cat << EOF > /etc/yum.repos.d/kubernetes.repo |
1 | yum install -y kubeadm-1.15.4 kubelet-1.15.4 kubectl-1.15.4 |
kubeadm master
添加外部etcd配置1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24#kubeadm config print init-defaults > kubeadm-config.yaml
cat << EOF > kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterConfiguration
controlPlaneEndpoint: "192.168.10.80:8443"
etcd:
external:
endpoints:
- https://192.168.10.81:2379
- https://192.168.10.82:2379
- https://192.168.10.83:2379
caFile: /etc/etcd/ssl/ca.pem
certFile: /etc/etcd/ssl/etcd.pem
keyFile: /etc/etcd/ssl/etcd-key.pem
kubernetesVersion: v1.15.4
imageRepository: gcr.azk8s.cn/google_containers
networking:
#podSubnet: 192.168.0.0/16 #默认calico网段与内网有重叠
podSubnet: 10.244.0.0/16
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs
EOF
第一台master1
2
3
4kubeadm init --config kubeadm-config.yaml --upload-certs
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
1 | Your Kubernetes control-plane has initialized successfully! |
添加第二、三台master1
2
3kubeadm join 192.168.10.80:8443 --token ytexwo.j1364ochwtv1t758 \
--discovery-token-ca-cert-hash sha256:1ebbb929926604f3126c875277d6b3f20a9bf35f13bfd01245b6babf74f7dd28 \
--control-plane --certificate-key 8d1f59c025b6b03a9f1585efadfb44edecf330c67c6a89ef5d83cf8bf38005df
kubeadm node
1 | kubeadm join 192.168.10.80:8443 --token ytexwo.j1364ochwtv1t758 \ |
calico
#calico默认pod网段为 192.168.0.0/161
2
3
4
5wget https://docs.projectcalico.org/v3.8/manifests/calico.yaml
POD_CIDR="10.244.0.0/16" \
sed -i -e "s?192.168.0.0/16?$POD_CIDR?g" calico.yaml
kubectl apply -f calico.yaml
安装有点久,可能需要几分钟。
多网卡指定1
2
3
4
5
6
7
8
9
10vim calico.yaml
spec:
containers:
- env:
- name: DATASTORE_TYPE
value: kubernetes
- name: IP_AUTODETECTION_METHOD # DaemonSet中添加该环境变量
value: interface=eth0 # 指定内网网卡
- name: WAIT_FOR_DATASTORE
value: "true"
1 | #未安装pod network时 Node STATUS 为NotReady |
1 | cat << EOF > ~/nginx-deployment.sh |
coredns
https://kubernetes.io/docs/tasks/administer-cluster/dns-debugging-resolution/1
2
3# kubectl get pod -nkube-system | grep coredns
coredns-5c98db65d4-mnlrr 1/1 Running 0 13h
coredns-5c98db65d4-xfjlb 1/1 Running 4 13h
1 | cat << EOF > busybox.yaml |
ingress-nginx
https://github.com/kubernetes/ingress-nginx/blob/master/docs/deploy/index.md1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/master/deploy/static/mandatory.yaml
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/master/deploy/static/provider/baremetal/service-nodeport.yaml
#kubectl get pods --all-namespaces -l app.kubernetes.io/name=ingress-nginx --watch
NAMESPACE NAME READY STATUS RESTARTS AGE
ingress-nginx nginx-ingress-controller-69969b98db-shr6j 1/1 Running 0 58m
# kubectl get svc -ningress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx NodePort 10.98.91.11 <none> 80:32634/TCP,443:30871/TCP 59m
POD_NAMESPACE=ingress-nginx
POD_NAME=$(kubectl get pods -n $POD_NAMESPACE -l app.kubernetes.io/name=ingress-nginx -o jsonpath='{.items[0].metadata.name}')
kubectl exec -it $POD_NAME -n $POD_NAMESPACE -- /nginx-ingress-controller --version
#curl 10.98.91.11:443
<html>
<head><title>404 Not Found</title></head>
<body>
<center><h1>404 Not Found</h1></center>
<hr><center>openresty/1.15.8.2</center>
</body>
</html>
dashboard
https://github.com/kubernetes/dashboard1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19wget https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml
vim kubernetes-dashboard.yaml
.....
image: gcr.azk8s.cn/google_containers/kubernetes-dashboard-amd64:v1.10.1
......
selector:
k8s-app: kubernetes-dashboard
type: NodePort
......
kubectl create -f kubernetes-dashboard.yaml
# kubectl get pods -n kube-system -l k8s-app=kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
kubernetes-dashboard-fcfb4cbc-f84jz 1/1 Running 0 2m9s
# kubectl get svc -n kube-system -l k8s-app=kubernetes-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes-dashboard NodePort 10.99.252.114 <none> 443:30202/TCP 106s
通过上面的 30202 端口去访问 Dashboard,注意要使用 https,Chrome不能访问可以使用Firefox访问:
使用Firefox访问:https://192.168.10.80:30202
创建具有全局所有权限的用户来登录Dashboard1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31cat << EOF > admin.yaml
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: admin
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
roleRef:
kind: ClusterRole
name: cluster-admin
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: admin
namespace: kube-system
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
EOF
kubectl apply -f admin.yaml
admin_token=$(kubectl get secret -n kube-system|grep admin-token|awk '{print $1}')
kubectl get secret $admin_token -o jsonpath={.data.token} -n kube-system |base64 -d #生成base64后的字符串
eyJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi10b2tlbi1scGRjZyIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50Lm5hbWUiOiJhZG1pbiIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6IjE0MWU2NTRmLWZhNWUtNGRkZS1iZGUxLTg3NDg0NTBkNTMyNCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlLXN5c3RlbTphZG1pbiJ9.SdKvGpq38TCYJOvQ_O7gax0nouhSeZEuuiA6MqFcxcM_8PwyiUzWq0fSzP5FF0gZdPuujYEh7CsJZYY1QQ22WT-UT5Ds6IHDBhvo0BmF5wPk_mlHUHTlUtdtFF_gZWVTZWsibQg2w2Vipzbza0nWsacRG5DYhEwxNBmUHgLJ53w0TpmZ6nonqD-Sva-BrGaim2mgPwe7trkpqSsUGYuxV7Ncwz8ZlG8S_vmwoO2r_3yc9S-62hSR0GMyrTx1JsESevv9tZzQvT1pW3eLdURa-WmhtM9WDOATQk2hk-JKl6KHVaCdgexKB6rWrelu_8uRmojbSf7SDSOJJqD1HwmwXw
使用上面base64解码后的字符串作为令牌登录Dashboard
metrics-server
1 | git clone https://github.com/kubernetes-incubator/metrics-server.git |
kube-proxy开启ipvs
这里已经在kubeadm init 开启ipvs了1
2kubectl describe cm -nkube-system kube-proxy | grep mode
mode: ipvs
后期开启ipvs1
2
3
4
5
6
7
8kubectl edit cm kube-proxy -n kube-system #将mode: "" 修改为mode: ipvs
mode: ipvs
#重置各个节点上的kube-proxy pod
kubectl get pod -n kube-system | grep kube-proxy | awk '{system("kubectl delete pod "$1" -n kube-system")}'
kubectl -nkube-system logs kube-proxy-d6rtv | grep ipvs
I1010 09:53:41.124950 1 server_others.go:170] Using ipvs Proxier.
移除node
1 | kubectl drain node5 --delete-local-data --force --ignore-daemonsets |
calico 清除
在相应节点操作1
2
3
4
5
6kubeadm reset
kubeadm reset --cri-socket unix:///run/containerd/containerd.sock -v 5
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
ipvsadm -C
modprobe -r ipip #删除tunl0接口
rm -rf /etc/cni/net.d/
节点维护
https://kubernetes.io/docs/tasks/administer-cluster/cluster-management/#maintenance-on-a-node
如节点内核升级或关机硬件修复,超过了5分钟以上(默认时间为5分钟,由--pod-eviction-timeout controller-manager 控制),则将此节点pod Terminating。如果pod存在相应的副本集,则在其他节点上启动Pod的新副本。
终止节点上的所有pod,及设置节点不可调度:1
kubectl drain $NODENAME
使节点可再次调度:1
kubectl uncordon $NODENAME
Logs flooded with systemd messages: Created slice libcontainer_70542_systemd_test_default.slice1
2echo 'if $programname == "systemd" and ($msg contains "Starting Session" or $msg contains "Started Session" or $msg contains "Created slice" or $msg contains "Starting user-" or $msg contains "Starting User Slice of" or $msg contains "Removed session" or $msg contains "Removed slice User Slice of" or $msg contains "Stopping User Slice of") then stop' >/etc/rsyslog.d/ignore-systemd-session-slice.conf
systemctl restart rsyslog
https://access.redhat.com/solutions/1564823
cpu: 100m # 0.1 core 1000M #1G
memory: 100Mi # 100M
镜像修改脚本
上文是直接使用gcr.azk8s.cn/google_containers,
若要使用原生k8s.gcr.io,则下载镜像后打tag
master 镜像下载1
2
3
4
5
6
7
8
9
10cat << EOF > ~/pull_master_images.sh
k8s_repo="gcr.azk8s.cn/google_containers"
kubeadm config images pull --image-repository=$k8s_repo --kubernetes-version="v1.15.4"
#将镜像修改回k8s.gcr.io
k8s_repo="gcr.azk8s.cn/google_containers"
docker images | grep $k8s_repo | awk '{print $1":"$2}' | sed 's#\('"$k8s_repo"'\)\(.*\)#docker tag \1\2 k8s.gcr.io\2#g' > ~/k8s_repo.sh && bash ~/k8s_repo.sh && rm -f ~/k8s_repo.sh
docker images | grep $k8s_repo | awk '{print $1":"$2}' | sed 's#'"\($k8s_repo\)"'#docker rmi \1#g' > ~/k8s_image_rm.sh && bash ~/k8s_image_rm.sh && rm -f ~/k8s_image_rm.sh
EOF
bash ~/pull_master_images.sh
worker 镜像下载1
2
3
4
5
6
7cat << EOF > ~/pull_worker_images.sh
k8s_repo="gcr.azk8s.cn/google_containers"
docker pull $k8s_repo/coredns:1.3.1
docker pull $k8s_repo/pause:3.1
docker images | grep $k8s_repo | awk '{print $1":"$2}' | sed 's#'"\($k8s_repo\)"'#docker rmi \1#g' > ~/k8s_image_rm.sh && bash ~/k8s_image_rm.sh && rm -f ~/k8s_image_rm.sh
EOF
bash ~/pull_worker_images.sh
efk
1 | mkdir elk && cd elk |
1 | # kubectl get pods -n kube-system -o wide|grep -E 'elasticsearch|fluentd|kibana' |
1 | # kubectl get service -n kube-system|grep -E 'elasticsearch|kibana' |
1 | kubectl logs -l k8s-app=kibana-logging -nkube-system |
1 | # kubectl cluster-info |
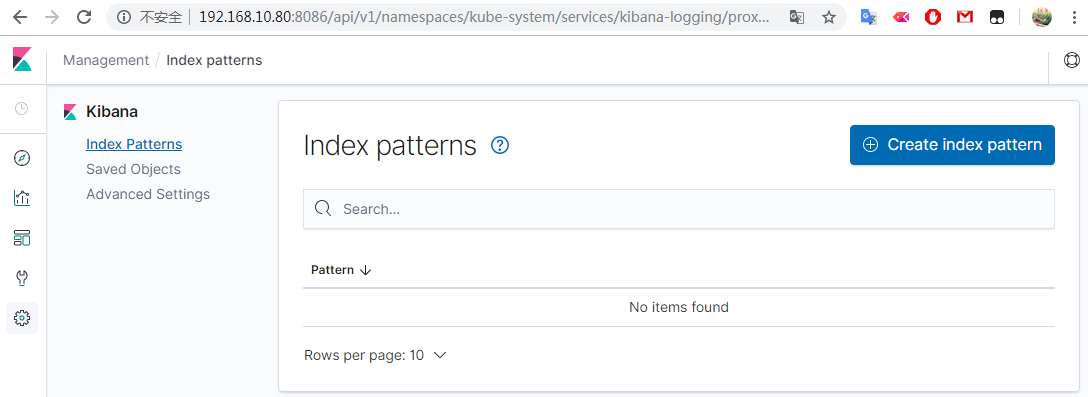
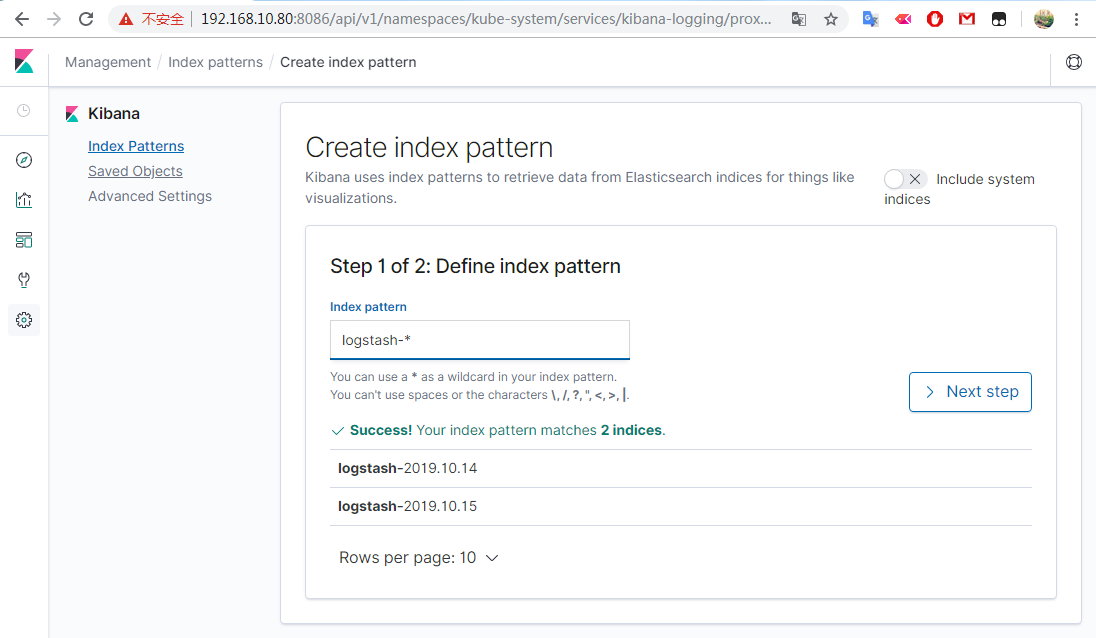
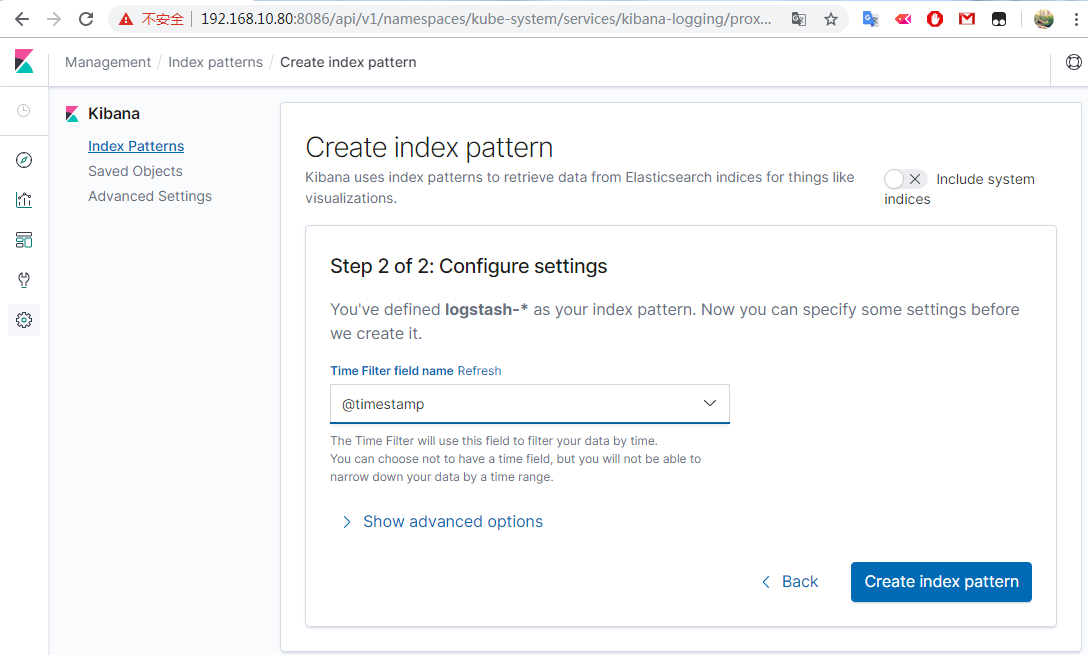
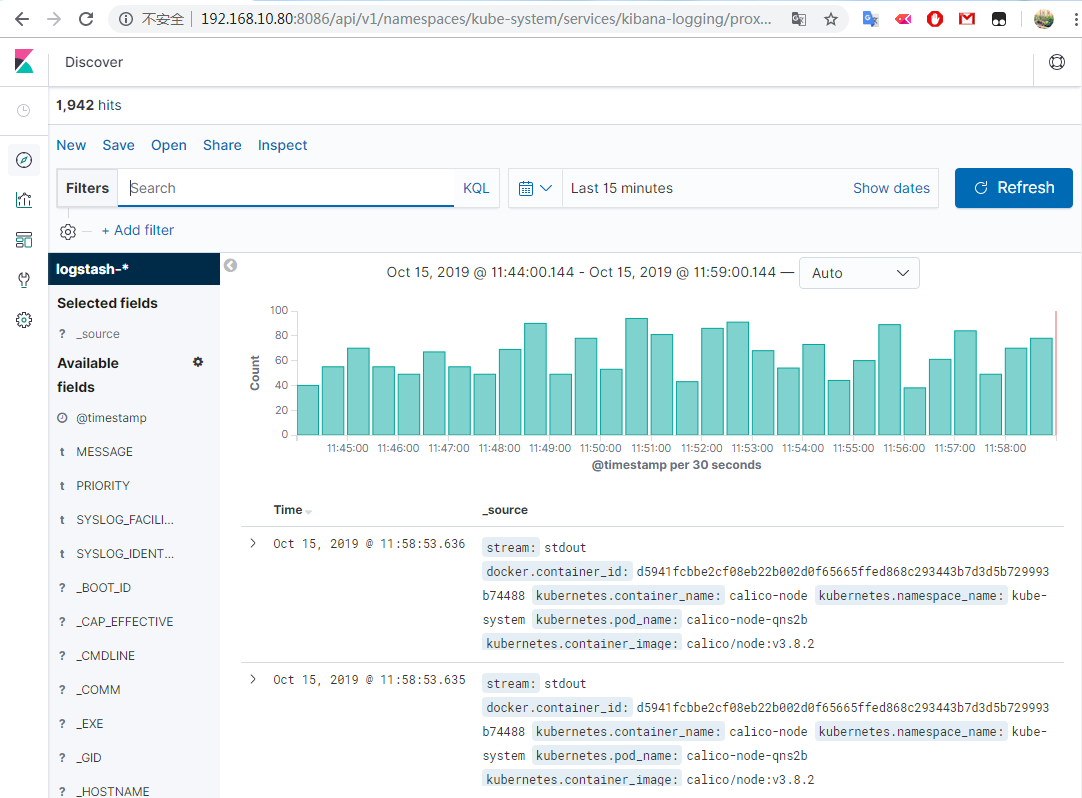
访问Kibana http://192.168.10.80:8086/api/v1/namespaces/kube-system/services/kibana-logging/proxy