什么是高可用
可用性如何定义
- 可用性(availability)是关于系统可供使用时间的表述,以不可用的时间为衡量指标。不可用时间越短,可用性越高。通常用 n 个 9 来描述。比如 4 个 9 的可用性(99.99%),是指一年中不可用时间在 52 分钟内,平均每周不可用时间在 1 分钟。
- 可靠性(reliability)是关于系统无故障时间间隔的描述,以发生故障的次数为衡量指标,故障次数越少,可靠性越高。
- 可维护性(maintainability)是指系统发生故障后,恢复的时间来描述。时间越短,可维护性越高。
高可用的实现
不同的应用场景对可用性的要求不同,对于银行、电信企业来说,一般都要求达到 5 个 9,然而 5 个 9 的服务可用性需要付出的代价和挑战是相当巨大的。例如,在基础设施方面,必须多路电源介入,必须支持蓄电设备,必须有独立的发电设备,所有设备和线路冗余备份,整个系统无单点故障。
对于软件服务,也必须做到无单点故障。因此,需要使用多台对外提供相同服务的服务器进行冗余,这些服务器之间需要保持实时通信,在主节点出现故障时,备用节点将主节点上的资源「抢夺」过来,由自己充当新的主节点对外提供服务。
高可用集群架构
通常,一个高可用集群的架构如下: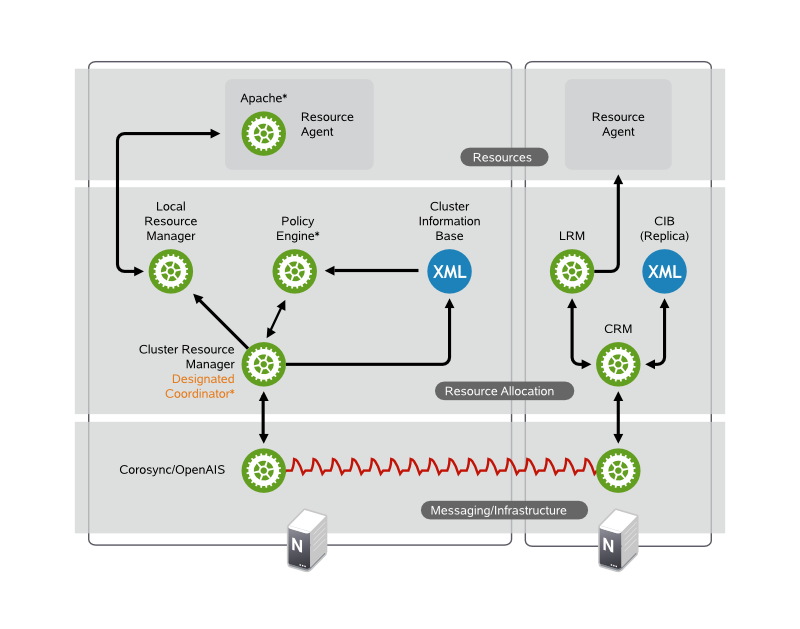
Messaging and Infrastructure Layer
最下面一层被称作集群事务信息层,这一层的主要作用是启动某个服务监听在某个套接字上,各个节点之间相互传递集群的状态信息,所有的高可用组件都运行在集群事务信息层之上。
Resource Allocation Layer
这一层建立在 Messaging Layer之上,主要负责集群资源的分配。集群的资源指提供一个集群服务所需要的所有组件(如 IP 地址,挂载的文件系统,服务进程等等)。这一层中由 CRM(Cluster Resource Manager)服务负责管理和分配集群资源。
Cluster Resource Manager
也称为 CRM,它接受通过 Messaging Layer 收集的集群事务信息,根据信息的状态完成运算和决策之后,采取相应的动作 —— 例如对集群资源的分配,对故障节点的处理,新的主节点的选举等等。它有两个子组件,PE(Policy Engne) 和 TE)Transaction Engine)。
Designated Coordinator
为了防止冲突,并不是所有节点的 CRM 都在进行决策的,集群中所有的决策动作应该在某一个节点上完成,这个节点被称为 DC(Designated Coordinator),即指派的事务协调员,只有 DC 上 CRM 真正的在进行集群事务决策和处理,DC 负责在集群级别进行事务的决策,并通知其他节点。
Policy Engine
策略引擎,它是 CRM 的子组件,负责对集群事务信息的状态变化做出响应的决策。
Transaction Engine
事务引擎,负责 Policy Engine 产生的决策的具体执行。
Cluster Information Base
CIB,集群信息库,其中存放了集群资源的配置信息,每一个节点中都有一份且完全相同。策略引擎会根据 CIB 中的定义来进行相应的决策。
Local Resource Manager 本地资源管理器,负责在每个节点上管理本地资源,接收由 TE 传递的指挥,并在本机执行。
Resource
Resource Agent
资源代理,负责某个集体资源的管理,它接受 LRM 的指令,完成对应资源的控制和管理,负责集群资源的状态监控,启动,停止和重启。通常是一个脚本程序。
资源类型
资源通常有这几种类型:
- primitive:只能运行在一个节点上
- clone:运行在所有节点上,如管理 STONITH 设备的进出呢个
- group:组资源,它是一个容器,包含一个或多个资源,这些资源可以通过资源组进行统一调度
- master/slava:运行在主/从两个节点上,如 DRBD
资源约束
定义资源间的约束关系:
- 位置约束:资源对节点的倾向程度
- 排列约束:资源间的依赖性和互斥性
- 顺序约束:资源启动或关闭时的顺序
RA 的类型
RA 通常是一个脚本,负责对一个具体的资源进行管理。它有下面几种类型:
- LSB(Linux Standard Base),符合Linux标准库的脚本,能够提供start(启动),restart(重启),stop(停止),status(状态监测),CentOS 系统中 /etc/rc.d/init.d 下的脚本都是 LSB RA
- OCF (Open Cluster Framwork),由某种 CRM 提供的遵照 OCF 规定的脚本,通常能够接受更多的参数,使用更加灵活。
- STONITH:用于管理 STONISH 设备的脚本。
节点失效策略
一个高可用集群可能有多台主机,如果一个节点失效,那么集群该如何处理?如果只是网络故障导致,节点间无法通信,那么多个节点间可能发生「脑裂」,即多个节点都认为自己是主节点,从而发生资源的互相抢占,如果对某个共享存储进行抢占甚至可能造成文件系统损坏。
仲裁设备
所有集群节点与仲裁设备连接,如果集群节点之间相互通信出现故障,那么节点会尝试与仲裁设备进行通信(如 ping,或向仲裁磁盘中写数据)。如果与仲裁设备的通信也失败,那么表示此节点已经失效,节点应该自行放弃资源的使用,从而避免资源的抢占。
资源隔离
为了杜绝资源抢占的发生,还可以对失效节点进行资源隔离,如使用 STONITH(Shoot The Other In The Head)设备,STONITH 设备可以直接切断失效节点的电源,使其彻底的失效,避免「半死不活」的状态。
投票系统
节点失效后,其他节点需要使用投票系统选举出新的主节点,通常票数超过半数的节点集群组成新的高可用集群。票数少于半数的节点则被认为失效,也即低于「法定票数」(without quorum)。
常用的高可用软件
常用的 Messaging Layer
- heartbeat(v1, v2, v3)
- corosync
- cman
- keepalived
常用的 CRM
- haresources(由 heartbeat v1 和 v2 提供)
- crm (heartbeat v2 提供)
- pacemaker (heartbeat v3 提供)
- rgmanager (cman)
转载来源:http://liaoph.com/high-availability/