企业中的应用场景
理论和实践上分析,GlusterFS 目前主要适用于大文件存储场景,对于小文件尤其是海量小文件,存储效率和访问性能都表现不佳。海量小文件 LOSF 问题是工业界和学术界公认的难题,GlusterFS 作为通用的分布式文件系统,并没有对小文件作额外的优化措施,性能不好也是可以理解的。
- Media - 文档、图片、音频、视频
- Shared storage - 云存储、虚拟化存储、HPC(高性能计算)
- Big data - 日志文件、RFID(射频识别)数据
文件大小大于 1MB 适合 GlusterFS,如果更小可以选用其他文件系统,如 FastFS 等,或者配置 CDN。
以 Docker 为代表的容器技术在云计算领域正扮演着越来越重要的角色,甚至一度被认为是虚拟化技术的替代品。企业级的容器应用常常需要将重要的数据持久化,方便在不同容器间共享。为了能够持久化数据以及共享容器间的数据,Docker 提出了 Volume 的概念。单机环境的数据卷难以满足 Docker 集群化的要求,因此需要引入分布式文件系统。目前开源的分布式文件系统有许多,例如 GFS,Ceph,HDFS,FastDFS,GlusterFS 等。GlusterFS 因其部署简单、扩展性强、高可用等特点,在分布式存储领域被广泛使用。本文主要介绍了如何利用 GlusterFS 为 Docker 集群提供可靠的分布式文件存储。
GlusterFS 分布式文件系统简介
GlusterFS 概述
GlusterFS (Gluster File System) 是一个开源的分布式文件系统,主要由 Z RESEARCH 公司负责开发。GlusterFS 是 S cale-Out 存储解决方案 Gluster 的核心,具有强大的横向扩展能力,通过扩展能够支持数PB存储容量和处理数千客户端。GlusterFS 借助 TCP/IP 或 InfiniBand RDMA 网络将物理分布的存储资源聚集在一起,使用单一全局命名空间来管理数据。GlusterFS 基于可堆叠的用户空间设计,可为各种不同的数据负载提供优异的性能。
GlusterFS 总体架构与组成部分如图1所示,它主要由存储服务器(Brick Server)、客户端以及 NFS/Samba 存储网关组成。不难发现,GlusterFS 架构中没有元数据服务器组件,这是其最大的设计这点,对于提升整个系统的性能、可靠性和稳定性都有着决定性的意义。
- GlusterFS 支持 TCP/IP 和 InfiniBand RDMA 高速网络互联。
- 客户端可通过原生 GlusterFS 协议访问数据,其他没有运行 GlusterFS 客户端的终端可通过 NFS/CIFS 标准协议通过存储网关访问数据(存储网关提供弹性卷管理和访问代理功能)。
- 存储服务器主要提供基本的数据存储功能,客户端弥补了没有元数据服务器的问题,承担了更多的功能,包括数据卷管理、I/O 调度、文件定位、数据缓存等功能,利用 FUSE(File system in User Space)模块将 GlusterFS 挂载到本地文件系统之上,实现 POSIX 兼容的方式来访问系统数据。
图1. GlusterFS 总体架构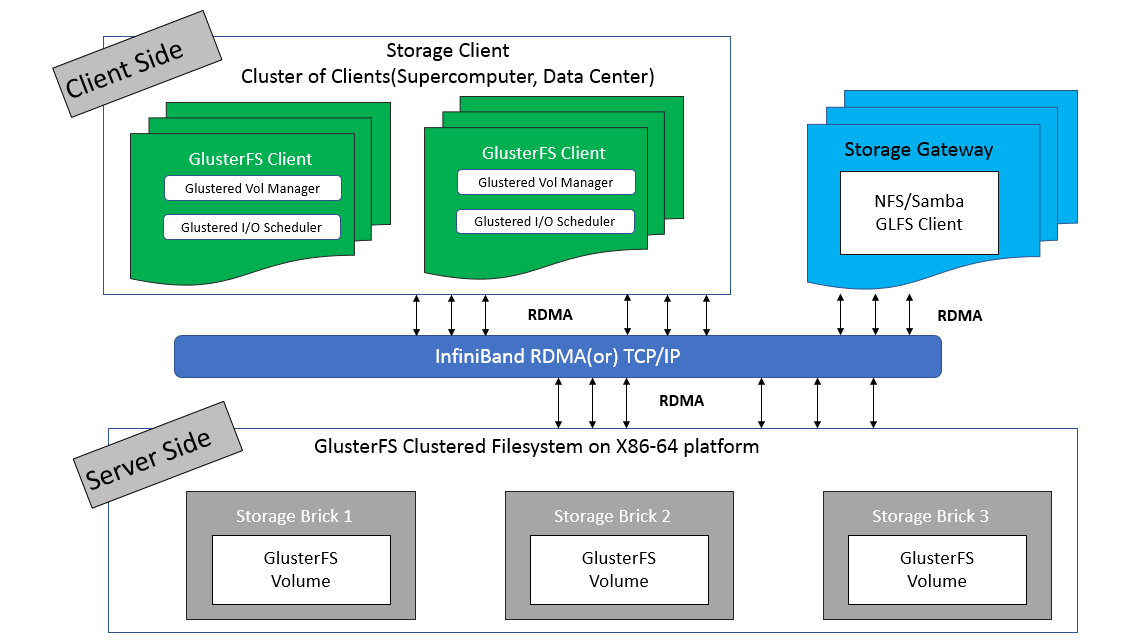
如图 1 中 GlusterFS 有非常多的术语,理解这些术语对理解 GlusterFS 的动作机理是非常重要的
表1给出了 GlusterFS 常见的名称及其解释。
| 名称 | 解释 |
|---|---|
| Brick | 最基本的存储单元,表示为trusted storage pool中输出的目录,供客户端挂载用。 |
| Volume | 一个卷。在逻辑上由N个bricks组成。 |
| FUSE | Unix-like OS上的可动态加载的模块,允许用户不用修改内核即可创建自己的文件系统。 |
| Glusterd | Gluster management daemon,要在trusted storage pool中所有的服务器上运行。 |
| POSIX | 一个标准,GlusterFS兼容。 |
GlusterFS卷类型
为了满足不同应用对高性能、高可用的需求,GlusterFS 支持 7 种卷,即 distribute 卷、stripe 卷、replica 卷、distribute stripe 卷、distribute replica 卷、stripe Replica 卷、distribute stripe replica 卷。其实不难看出,GlusterFS 卷类型实际上可以分为 3 种基本卷和 4 种复合卷,每种类型的卷都有其自身的特点和适用场景。
基本卷
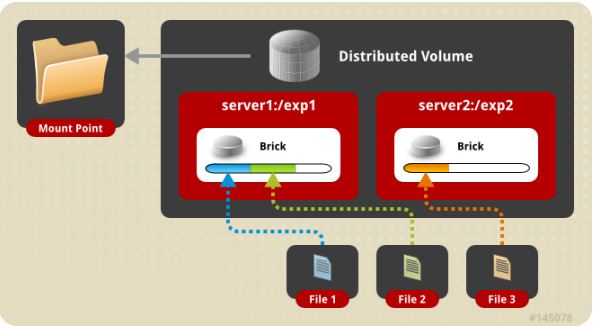
(1) distribute volume 分布式卷
基于 Hash 算法将文件分布到所有 brick server,只是扩大了磁盘空间,不具备容错能力。由于distribute volume 使用本地文件系统,因此存取效率并没有提高,相反会因为网络通信的原因使用效率有所降低,另外本地存储设备的容量有限制,因此支持超大型文件会有一定难度。
(2) stripe volume 条带卷
类似 RAID0,文件分成数据块以 Round Robin 方式分布到 brick server 上,并发粒度是数据块,支持超大文件,大文件的读写性能高。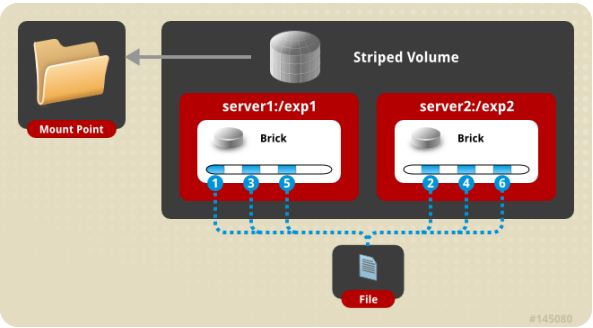
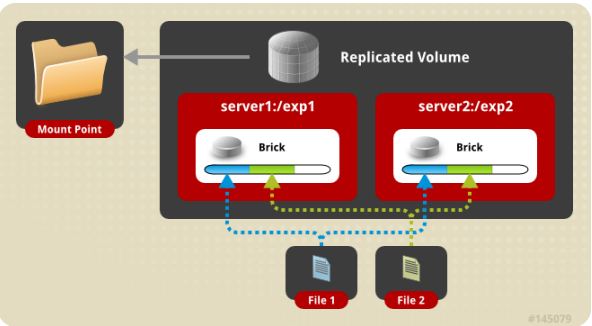
(3) replica volume 复制卷
文件同步复制到多个 brick 上,文件级 RAID1,具有容错能力,写性能下降,读性能提升。Replicated 模式,也称作 AFR(Auto File Replication),相当于 RAID1,即同一文件在多个镜像存储节点上保存多份,每个 replicated 子节点有着相同的目录结构和文件,replica volume 也是在容器存储中较为推崇的一种。
复合卷
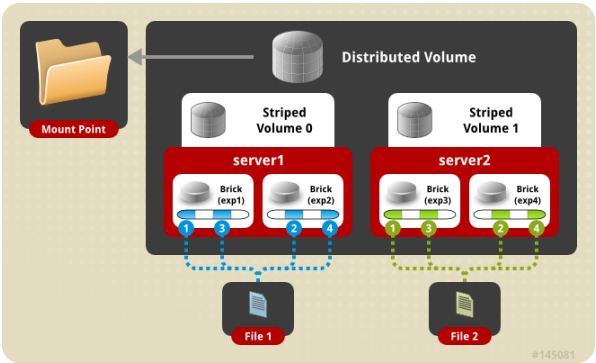
(4) distribute stripe volume 分布式条带卷
Brick server 数量是条带数的倍数,兼具 distribute 和 stripe 卷的特点。分布式的条带卷,volume 中 brick 所包含的存储服务器数必须是 stripe 的倍数(>=2倍),兼顾分布式和条带式的功能。每个文件分布在四台共享服务器上,通常用于大文件访问处理,最少需要 4 台服务器才能创建分布条带卷。
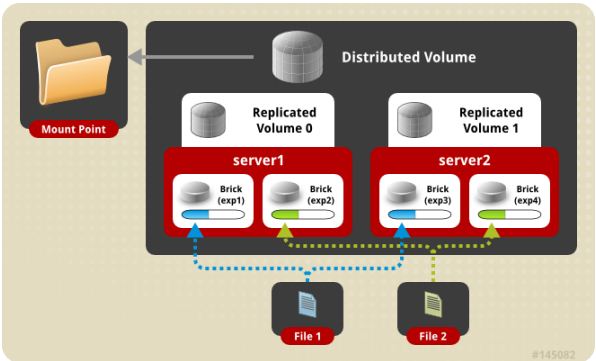
(5) distribute replica volume 分布式复制卷
Brick server 数量是镜像数的倍数,兼具 distribute 和 replica 卷的特点,可以在 2 个或多个节点之间复制数据。分布式的复制卷,volume 中 brick 所包含的存储服务器数必须是 replica 的倍数(>=2倍),兼顾分布式和复制式的功能。
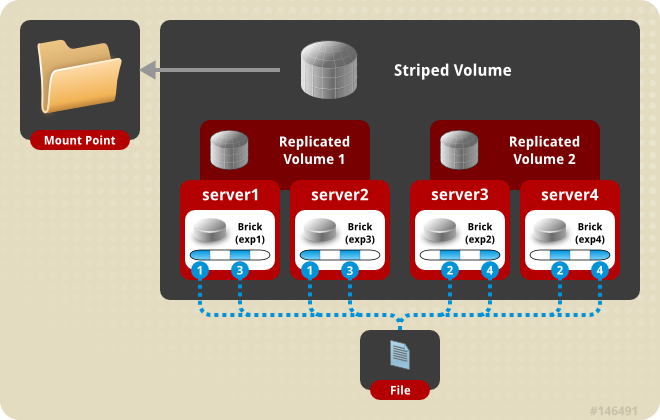
6) stripe replica volume 条带复制卷
类似 RAID 10,同时具有条带卷和复制卷的特点。
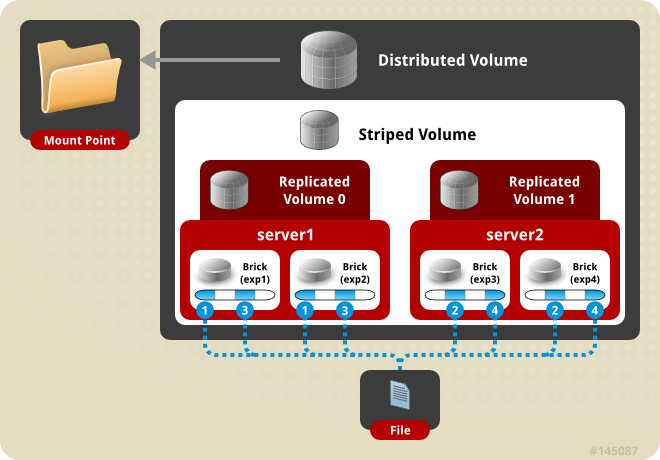
(7) distribute stripe replica volume:分布式条带复制卷
三种基本卷的复合卷,通常用于类 Map Reduce 应用。
GlusterFS 常用命令
GlusterFS 客户端提供了非常丰富的命令用来操作节点、卷,表2给出了常用的一些命令。在与容器对接过程中,通过我们需要创建卷、删除卷,以及设定卷的配额等功能,并且后续这些功能也需要 REST API 化,方便通过HTTP请求的方式来操作卷。
表2. GlusterFS 客户端常用命令
| 命令 | 功能 |
|---|---|
| gluster peer probe | 添加节点 |
| gluster peer detach | 移除节点 |
| gluster volume create | 创建卷 |
| gluster volume start | 启动卷 |
| gluster volume stop | 停止卷 |
| gluster volume delete | 删除卷 |
| gluster volume quota enable | 开启卷配额 |
| gluster volume quota enable | 关闭卷配额 |
| gluster volume quota limit-usage | 设定卷配额 |
GlusterFS 集群搭建
本文将以 CentOS 7 为例安装 2 个节点的 GlusterFS 集群。每个服务节点需要有一个额外的盘符。具体请参考下面步骤:
(1). 格式化磁盘
1 | yum install lvm2 xfsprogs -y |
(2). 添加gluster源
1 | yum install centos-release-gluster -y |
(3). 安装启动glusterfs
1 | yum install xfsprogs glusterfs-server -y |
(4). 配置peer
1 | gluster peer probe <IP|HOSTNAME> #添加其他gluster节点 |
(5). 当出现下列信息时表示集群搭建成功
1 | gluster peer status |
(6). 创建Volume
1 | gluster volume create <VOLUME_NAME> replica 2 \ |
(7). 启动Volume
1 | gluster volume start <VOLUME_NAME> |
GlusterFS 客户端配置
(1). 添加gluster源
1 | yum install centos-release-gluster -y |
(2). 安装glusterfs client
1 | yum install glusterfs-client -y |
(3). 挂载gluster卷
1 | mount -t glusterfs node1:<VOLUME_NAME> /mnt/local-volume |
扩展peer
注:先设置分区1
2gluster peer probe <IP|HOSTNAME>
gluster volume add-brick <VOLUME_NAME> replica 3 <IP|HOSTNAME>:/glusterfs/brick/<VOLUME_NAME> force
删除peer
原replica 1x3 移除,变成:replica 1x2 的集群1
gluster volume remove-brick <VOLUME_NAME> replica 2 <IP|HOSTNAME>:/glusterfs/brick/<VOLUME_NAME> force
查看 Volume 信息
1 | gluster volume info |
Docker GlusterFS Volume 插件
接下来,我们再来看GlusterFS如何作为Docker的存储。Docker Volume是一种可以将容器以及容器生产的数据分享开来的数据格式,我们可以使用宿主机的本地存储作为Volume的提供方,也可以使用Volume Plugin接入许多第三方的存储。 GitHub就有一个Docker GlusterFS Volume Plugin,方便我们将GlusterFS挂载到容器中。具体步骤如下:
(1). 获取docker-volume-glusterfs
1 | go get github.com/calavera/docker-volume-glusterfs |
考虑到搭建golang环境有一定的复杂性,我们也可以采用golang容器来获取该应用
(2). 拷贝docker-volume-glusterfs至/usr/bin
1 | cp ./docker-volume-glusterfs /usr/bin |
(3). 声明gluster服务集群
1 | docker-volume-glusterfs -servers node1:node2 |
(4). 指定volume
docker run –volume-driver glusterfs –volume datastore:/data alpine touch /data/hello
这里的datastore即我们在glusterfs集群中创建的volume,但需要事先手动创建
GlusterFS REST API 服务搭建
上述步骤虽然实现了 GlusterFS 作为 Docker 存储方案,但 GlusterFS 卷仍需要手动创建。为了自动化地管理 GlusterFS 卷,我们将卷操作封装成 REST API。 GitHub上的 glusterfs-rest 将 GlusterFS 基础操作使用 Python 封装成了 REST API,但是它没有将 Volume 容量限制等功能封装起来,而我们项目中这个功能又是必须的,不过稍加修改后就可以实现容量限制的功能。
(1). 克隆代码
1 | git clone https://github.com/aravindavk/glusterfs-rest.git |
(2). 修改glusterfs-rest/glusterfsrest/cli/ volume.py create方法
1 | def create(name, bricks, replica=0, stripe=0, transport='tcp', force=False, |
(3). 修改glusterfs-rest/glusterfsrest/doc/api-1.0.yml Create内容
1 | # ----------------------------------------------------------------------------- |
(4). 安装依赖
1 | yum install python-setuptools -y |
(5). 启动服务
1 | cd glusterfs-rest |
(6). 拷贝gunicorn
1 | cp localgunicorn bin/ |
(7). 启动服务
1 | glusterrest port 80 |
服务启动后,我们可以通过 http://<node_ip>/ api/1.0/doc 访问 API 的具体使用方法,主要封装的 API 见表 3。
表3. Gluster-rest 封装 API
| 功能描述 | HTTP请求方法 | URL |
|---|---|---|
| 查看卷列表 | GET | /api/1.0/volumes |
| 查看单独卷信息 | GET | /api/1.0/volume/:name |
| 创建卷 | POST | /api/1.0/volume/:name |
| 删除卷 | DELETE | /api/1.0/volume/:name |
| 启动卷 | PUT | /api/1.0/volume/:name/start |
| 停止卷 | PUT | /api/1.0/volume/:name/stop |
| 重启卷 | PUT | /api/1.0/volume/:name/restart |
| 获取集群节点信息 | GET | /api/1.0/peers |
| 添加节点 | POST | /api/1.0/peer/:hostname |
| 删除节点 | DELETE | /api/1.0/peer/:hostname |
基于 GlusterFS 实现数据持久化案例
非持久化MYSQL数据库容器
1 | # (1). 创建mysql_1 |
持久化 MYSQL 数据库容器
1 | # (1). 创建Volume |
这里我们可以看到新创建的容器包含了之前创建的数据库 mydb,也就实现了我们说的数据持久化效果。
小结
GlusterFS 作为一种开源分布式存储组件,具有非常强大的扩展能力,同时也提供了非常丰富的卷类型,能够轻松实现PB级的数据存储。本文基于 docker glusterfs volume 插件和 gluster-rest API 封装,实现了容器的集群分布式存储功能。Docker 本身提供了本地存储的方案,但无法跨越主机,因此容器一旦被销毁后,如果不是落在先前的宿主机上运行也就意味着数据丢失。本文实现的 GlusterFS 存储方案,卷信息不随 Docker 宿主机的变更而发生变化,因此能够方便实现 Docker 集群的横向扩展。本文为 Docker 集群提供持久化的功能,例如关系型数据、文件服务等,提供了非常有价值的参考。
转载自:基于 GlusterFS 实现 Docker 集群的分布式存储